Ghost BatchNorm
Tags: Method,Vision,Regularization,Decreased GPU Throughput, Increased Accuracy
During training, BatchNorm normalizes a batch of inputs to have a mean of 0 and variance of 1. Ghost BatchNorm instead splits the batch into multiple “ghost” batches, each containing ghost_batch_size samples, and normalizes each one to have a mean of 0 and variance of 1. This causes training with a large batch size to behave more similarly to training with a small batch size and acts as a regularizer.
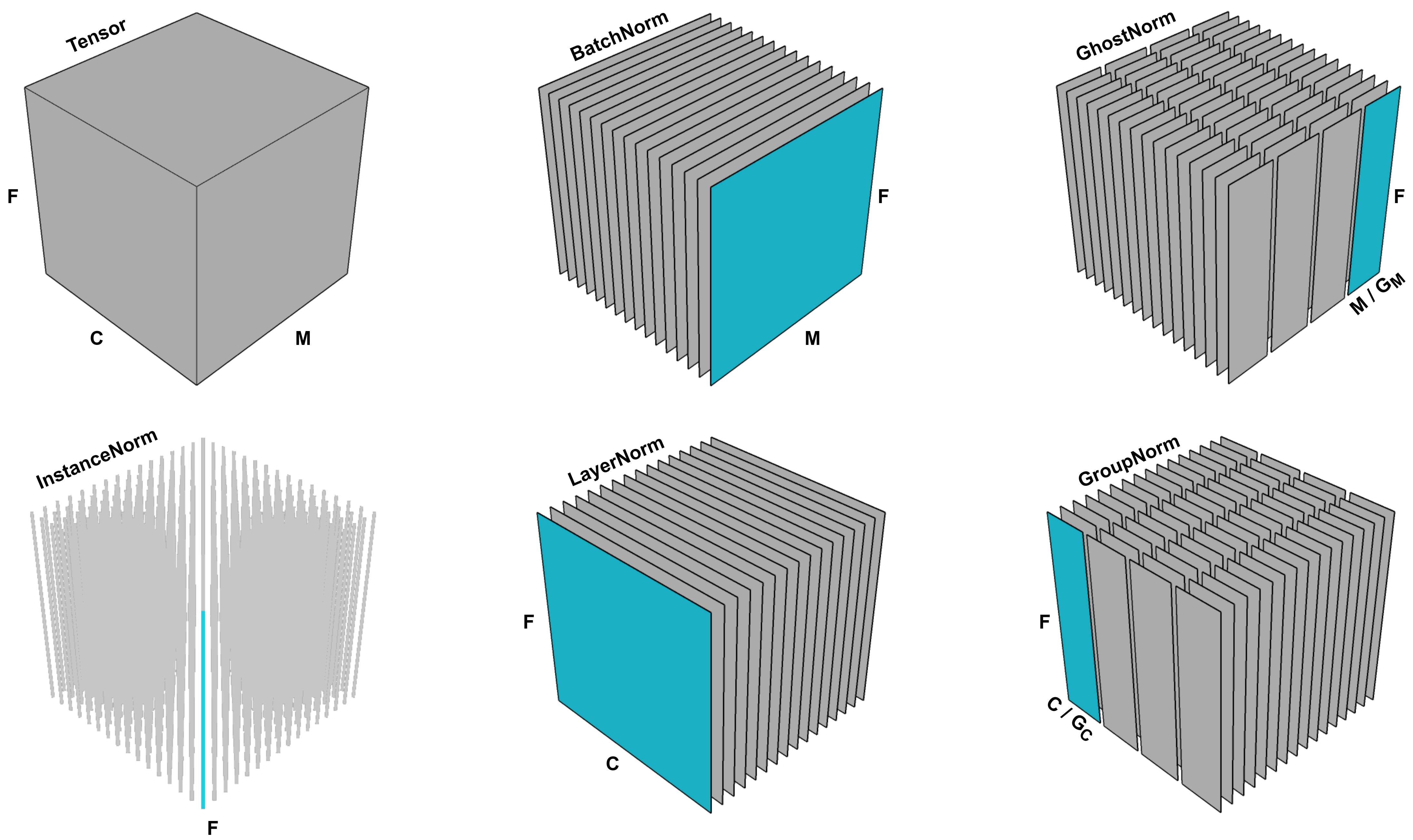
Visualization of different normalization methods, from “A New Look at Ghost Normalization”, cited below. Here \(\mathbf{F}\) represents the spatial dimensions (such as height and width), \(\mathbf{C}\) represents the channel dimension, and \(\mathbf{M}\) represents the sample dimension within a batch. Ghost batch normalization (upper right) is a modified version of batchnorm that normalizes the mean and variance for disjoint sub-batches of the full batch.
Attribution
Train Longer, Generalize Better: Closing the Generalization Gap in Large Batch Training of Neural Networks by Elad Hoffer, Itay Hubara, and Daniel Sourry (2017).
A New Look at Ghost Normalization by Neofyos Dimitriou and Ognjen Arandjelovic (2020).
Hyperparameters
ghost_batch_size- The number of samples within each ghost batch. Must be less than or equal to the per-device batch size in multi-gpu training.
Applicable Settings
Applicable whenever BatchNorm is used (typically in vision settings), but may be especially effective when using large batch sizes.
Example Effects
The original paper reports a 0-3% accuracy change across a number of models and small-scale datasets.
One author obtained a 13% speedup at fixed accuracy on a set of CIFAR-10 experiments.
For ResNet-50 on ImageNet, we’ve found Top-1 accuracy changes between -.3% to +.3% and training throughput decreases of around 5% fewer samples/sec.
Implementation Details
Our implementation works by splitting an input batch into equal-sized chunks along the sample dimension and feeding each chunk into a normal batchnorm module. This yields slightly different mean and variance statistics compared to using normal a batchnorm module. The difference stems from the moving average over a sequence of chunks not being equal to the true average of the chunks.
Suggested Hyperparameters
Ghost batch sizes of 16, 32, and 64 seem to consistently yield accuracy close to the baseline, and sometimes higher.
Considerations
For small ghost batch sizes, this method might run more slowly than normal batch normalization. This is because our implementation uses a number of operations proportional to the number of ghost batches, and each PyTorch operation has a small amount of overhead. This overhead is inconsequential when doing large chunks of “work” per operation (i.e., operating on large inputs), but can matter when the inputs are small.
This method may either help or harm the model’s accuracy. There is some evidence that it is more likely to help when using larger batch sizes (many thousands).
Composability
As a general rule, combining multiple regularization-based methods yields diminishing improvements to accuracy. This holds true for Ghost BatchNorm.
Code
- class composer.algorithms.ghost_batchnorm.GhostBatchNorm(ghost_batch_size: int = 32)[source]
Replaces batch normalization modules with Ghost Batch Normalization modules that simulate the effect of using a smaller batch size.
Works by spliting input into chunks of
ghost_batch_sizesamples and running batch normalization on each chunk separately. Dim 0 is assumed to be the sample axis.Runs on
Event.INITand should be applied both before the model has been moved to accelerators and before the model’s parameters have been passed to an optimizer.- Parameters
ghost_batch_size – size of sub-batches to normalize over
- apply(event: composer.core.event.Event, state: composer.core.state.State, logger: Optional[composer.core.logging.logger.Logger] = None) None[source]
Applies GhostBatchNorm by wrapping existing BatchNorm modules
- match(event: composer.core.event.Event, state: composer.core.state.State) bool[source]
Runs on Event.INIT
- class composer.algorithms.ghost_batchnorm.GhostBatchNormHparams(ghost_batch_size: int)[source]
See
GhostBatchNorm
- composer.algorithms.ghost_batchnorm.apply_ghost_batchnorm(model: torch.nn.modules.module.Module, ghost_batch_size: int) torch.nn.modules.module.Module[source]
Replace batch normalization modules with ghost batch normalization modules.
Must be run before the model has been moved to accelerators and before the model’s parameters have been passed to an optimizer.
- Parameters
model – model to transform
ghost_batch_size – size of sub-batches to normalize over