ALiBi
Tags: NLP, Decreased Wall Clock Time, Increased Accuracy, Increased GPU,
Throughput, Reduced GPU Memory Usage, Reduced GPU Usage, Method,
Memory Reduction, Speedup
TL;DR
ALiBi (Attention with Linear Biases) dispenses with position embeddings for tokens in transformer-based NLP models, instead encoding position information by biasing the query-key attention scores proportionally to each token pair’s distance. ALiBi yields excellent extrapolation to unseen sequence lengths compared to other position embedding schemes. We leverage this extrapolation capability by training with shorter sequence lengths, which reduces the memory and computation load.
Attribution
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation by Ofir Press, Noah A. Smith, and Mike Lewis. Released on arXiv in 2021.
Applicable Settings
ALiBi was developed and tested on NLP tasks, but it could conceivably be applied to any 1d sequence-modeling task.
Hyperparameters
train_sequence_length_scaling- The amount by which to scale the length of training sequences. One batch of training data tokens will be reshaped from size (sequence_length,batch) to (sequence_length*train_sequence_length_scaling,batch/train_sequence_length_scaling). In order to ensure data tensors are a valid shape,train_sequence_length_scalingshould equal \(2^{-n}\), where n is an integer.position_embedding_attribute- The model’s attribute containing the position embeddings, which ALiBi requires be removed. We achieve this by zeroing and freezing position embedding parameters. Example: In our GPT2 model family (which uses HuggingFace), the position embeddings aretransformer.wpe.attention_module_name- The module/class that will have its self-attention function replaced. Example: In our GPT2 model family, the self-attention module istransformers.models.gpt2.modeling_gpt2.GPT2Attention.attr_to_replace- The attribute ofattention_module_namethat performs self-attention and will be replaced by the self-attention function implementing ALiBi. Example: In our GPT2 model family, the self-attention is computed by the function_attn.alibi_attention- Path to the new self-attention function implementing ALiBi. Example: In our codebase,alibi_attentionfor the GPT2 model family iscomposer.algorithms.alibi.gpt2_alibi._attn.mask_replacement_function- Path to function to replace model’s attention mask. This is sometimes necessary for evaluating on sequence lengths longer than the model was initialized to accommodate.max_sequence_length- Maximum allowable sequence length.heads_per_layer- Number of attention heads per layer.
Example Effects
Press et al. report that models trained with ALiBi maintain similar performance even when tested on sequences 5-10x longer than they were trained on. ALiBi’s extrapolation capabilities can be leveraged to train on shorter sequences. This is desirable because the number of operations required to compute self-attention and the GPU memory usage required to store the resulting representations both increase with the square of the sequence length. In one example scenario, Press et al. reported training to equal perplexity in 90% of the time and utilizing 90% of the GPU memory compared to a baseline model with sinusoidal position embeddings. Our experiments showed that ALiBi could reduce perplexity by 0.2-0.6, train models in 85% of the time, and utilize 78-86% of the GPU memory compared to baseline models (See Considerations below for detailed results).
Implementation Details
ALiBi dispenses with traditional position embeddings and instead adds a static, non-learned bias to the query-key attention scores (or attention weights). This bias is proportional to the distance between the query and key tokens that comprise each attention score. The distances are scaled by m, a head-specific scalar that is fixed during training.
|
|---|
The matrix on the left depicts the attention score for each key-query token pair. |
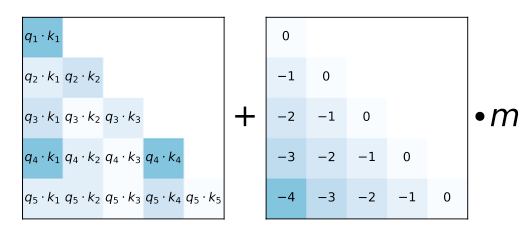
Press et al. found that learning m did not lead to strong extrapolation, and instead set
where \(H\) is the number of heads in a layer and \(h\) is the head index.
Suggested Hyperparameters
We found that train_sequence_length_scaling=0.25 provided appreciable speed and accuracy gains for models evaluated at sequence length = 1024 (see Example Effects section above and Considerations below for detailed results), and found that performance degraded for train_sequence_length_scaling≤0.125.
Considerations
We conducted experiments on the GPT2 model family trained on OpenWebText on 8x NVIDIA A100s, and compared baseline models with learned position embeddings and training sequence length = 1024 to models using ALiBi with train_sequence_length_scaling=0.25 (i.e. train sequence length 256). Our results are shown in the table below.
When training on sequences of identical length, Press et al. report that ALiBi increases training time and memory usage by ~1% compared to models with sinusoidal position embeddings. Press et al. also report that models trained with ALiBi on sequences of length 1024 maintained similar levels of performance when evaluated on sequences of 5-10x in length. We observed that performance significantly degraded for ALiBi models trained on sequence lengths ≤128, implying that very short sequences (≤128 tokens) may be irreconcilably out-of-distribution with regard to longer sequences. Considering our results together with those of Press et al. lead to the suggestion that models with ALiBi should not be trained on sequences ≤256 or train_sequence_length_scaling≤0.03125, whichever is larger.
Name |
Perplexity |
Perplexity Difference |
Wall Clock Train Time (s) |
Train Time (ALiBi/Baseline) |
GPU Memory Allocated (%) |
GPU Allocated (ALiBi/Baseline) |
|---|---|---|---|---|---|---|
GPT2-52m baseline |
30.779±0.06 |
9801±1 |
92.91 |
|||
GPT2-52m ALiBi 0.25x |
30.542±0.03 |
0.24 |
8411±5 |
0.86 |
79.92 |
0.86 |
GPT2-83m baseline |
26.569 |
17412 |
97.04 |
|||
GPT2-83m ALiBi 0.25x |
26.19±0.02 |
0.38 |
14733±3 |
0.85 |
80.97 |
0.83 |
GPT2-125m baseline |
24.114 |
30176 |
95.96 |
|||
GPT2-125m ALiBi 0.25x |
23.487 |
0.63 |
25280 |
0.84 |
74.83 |
0.78 |
Numbers reported are mean±{max,min} when available. The number of training tokens were as follows: GPT2-52m: 3.4B tokens; GPT2-83m: 5.6B tokens; GPT2-114m: 6.7B tokens. See Model Cards for model details.
Composability
There are currently no contraindications for ALiBi’s usage; it plays nicely with other NLP speedup techniques.
Code
- class composer.algorithms.alibi.Alibi(position_embedding_attribute: str, attention_module_name: str, attr_to_replace: str, alibi_attention: str, mask_replacement_function: str, heads_per_layer: int, max_sequence_length: int, train_sequence_length_scaling: float)[source]
AliBi (Attention with Linear Biases) dispenses with position embeddings and instead directly biases attention matrices such that nearby tokens attend to one another more strongly.
ALiBi yields excellent extrapolation to unseen sequence lengths compared to other position embedding schemes. We leverage this extrapolation capability by training with shorter sequence lengths, which reduces the memory and computation load.
This algorithm modifies the model and runs on Event.INIT. This algorithm should be applied before the model has been moved to accelerators.
- Parameters
heads_per_layer – number of attention heads per layer
max_sequence_length – maximum sequence length that the model will be able to accept without returning an error
position_embedding_attribute – attribute for position embeddings. For example in HuggingFace’s GPT2, the position embeddings are “transformer.wpe”.
attention_module_name – module/class that will have its self-attention function replaced. For example, in HuggingFace’s GPT, the self-attention module is “transformers.models.gpt2.modeling_gpt2.GPT2Attention”.
attr_to_replace – attribute that self-attention function will replace. For example, in HuggingFace’s GPT2, the self-attention function is “_attn”.
alibi_attention – Path to new self-attention function in which ALiBi is implemented. Used to replace “{attention_module}.{attr_to_replace}”.
mask_replacement_function – Path to function to replace model’s attention mask. This is sometimes necessary for evaluating on sequence lengths longer than the model was initialized to accommodate.
train_sequence_length_scaling – Amount by which to scale training sequence length. One batch of training data will be reshaped from size (sequence_length, batch) to (sequence_length*sequence_length_fraction, batch/sequence_length_fraction).
- apply(event: composer.core.event.Event, state: composer.core.state.State, logger: composer.core.logging.logger.Logger) Optional[int][source]
Replace model’s existing attention mechanism with AliBi
- match(event: composer.core.event.Event, state: composer.core.state.State) bool[source]
Runs on Event.INIT
- composer.algorithms.alibi.apply_alibi(model: torch.nn.modules.module.Module, heads_per_layer: int, max_sequence_length: int, position_embedding_attribute: str, attention_module: torch.nn.modules.module.Module, attr_to_replace: str, alibi_attention: Callable, mask_replacement_function: Optional[Callable]) None[source]
Removes position embeddings and replaces the attention function and attention mask according to AliBi.
- Parameters
model – model to transform
heads_per_layer – number of attention heads per layer
max_sequence_length – maximum sequence length that the model will be able to accept without returning an error
position_embedding_attribute – attribute for position embeddings. For example in HuggingFace’s GPT2, the position embeddings are “transformer.wpe”.
attention_module – module/class that will have its self-attention function replaced. For example, in HuggingFace’s GPT, the self-attention module is transformers.models.gpt2.modeling_gpt2.GPT2Attention.
attr_to_replace – attribute that self-attention function will replace. For example, in HuggingFace’s GPT2, the self-attention function is “_attn”.
alibi_attention – new self-attention function in which ALiBi is implemented. Used to replace “{attention_module}.{attr_to_replace}”.
mask_replacement_function – function to replace model’s attention mask. This is sometimes necessary for evaluating on sequence lengths longer than the model was initialized to accommodate.