🧊 Stochastic Depth (Block)#
AKA: Progressive Layer Dropping
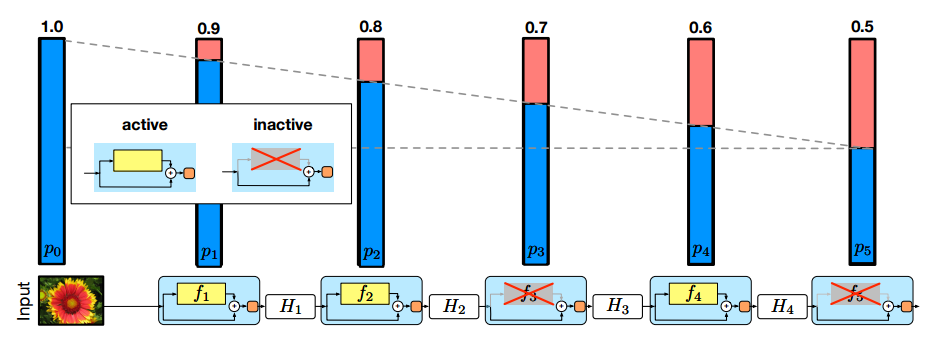
From Deep Networks with Stochastic Depth by Huang et al. 2016
Tags: Method,NLP, Networks with Residual Connections, Vision,Regularization, Speedup,Decreased GPU Throughput, Decreased Wall Clock Time, Reduced GPU Memory Usage
TL;DR#
Block-wise stochastic depth assigns every residual block a probability of dropping the transformation function, leaving only the skip connection, to regularize and reduce the amount of computation.
Attribution#
Deep Networks with Stochastic Depth by Gao Huang, Yu Sun, Zhuang Liu, Daniel Sedra, and Killian Weinberger. Published in ECCV in 2016.
Accelerating Training of Transformer-Based Language Models with Progressive Layer Dropping by Minjia Zhang and Yuxiong He. Published in NeurIPS 2020.
Applicable Settings#
Block-wise stochastic depth is only applicable to network architectures that include skip connections since they make it possible to drop parts of the network without disconnecting the network.
Hyperparameters#
stochastic_method- Specifies the version of the stochastic depth method to use. Block-wise stochastic depth is specified bystochastic_method=block.target_block_name- The reference name for the module that will be replaced with a functionally equivalent stochastic block. For example,target_block_name=ResNetBottleNeckwill replace modules in the model namedResNetBottleNeck.drop_rate- The base probability of dropping a block.drop_distribution- How thedrop_rateis distributed across the model’s blocks. The two possible values are “uniform” and “linear”. “Uniform” assigns a singledrop_rateacross all blocks. “Linear” linearly increases the drop rate according to the block’s depth, starting from 0 at the first block and ending withdrop_rateat the last block.use_same_gpu_seed- Set to false to have the blocks to drop sampled independently on each GPU. Only has an effect when training on multiple GPUs.drop_warmup- Percentage of training to linearly warm-up the drop rate from 0 todrop_rate.
Example Effects#
For ResNet-50 on ImageNet, we used drop_rate=0.2 and drop_distribution=linear. We measured a 5% decrease in training wall-clock time while maintaining a similar accuracy to the baseline. For ResNet-101 on ImageNet, we used drop_rate=0.4 and drop_distribution=linear. We measured a 10% decrease in training wall-clock time while maintaining an accuracy within 0.1% of the baseline.
Huang et al. used drop_rate=0.5 and drop_distribution=linear for ResNet-110 on CIFAR-10/100 and for ResNet-152 on ImageNet. They report that these hyperparameters result in a 25% reduction in training time with absolute accuracy differences of +1.2%, +2.8%, and -0.2% on CIFAR-10, CIFAR-100, and ImageNet, respectively.
Implementation Details#
Every residual block in the model has an independent probability of skipping the transformation component by utilizing only the skip connection. This effectively drops the block from the computation graph for the current iteration. During inference, the transformation component is always used and the output is scaled by (1 - drop rate). This scaling compensates for skipping the transformation during training.
When using multiple GPUs to train, setting use_same_gpu_seed=False assigns each GPU a different random seed for sampling the blocks to drop. This effectively drops different proportions of the batch at each block, making block-wise stochastic depth similar to example-wise stochastic depth. Typically, the result is increased accuracy and decreased throughput compared to dropping the same blocks across GPUs.
As proposed by Zhang et al., drop warmup specifies a portion of training to linearly increase the drop rate from 0 to drop_rate. This provides stability during the initial phase of training, improving convergence in some scenarios.
Suggested Hyperparameters#
The drop rate will primarily depend on the model depth. For ResNet50 on ImageNet, we find that a drop rate of 0.2 with a linear drop distribution has the largest reduction in training time while maintaining the same accuracy. We do not use any drop warmup and drop the same blocks across all GPUs.
drop_rate = 0.2drop_distribution = "linear"drop_warmup = 0.0duruse_same_gpu_seed = True
Considerations#
Because block-wise stochastic depth reduces model capacity by probabilistically excluding blocks from training updates, the increased capacity of larger models allows them to accommodate higher block drop rates. For example, the largest drop rate that maintains accuracy on ResNet-101 is almost double the drop rate on ResNet-50. If using a model with only a few blocks, it is best to use a small drop rate or to avoid stochastic depth.
Although use_same_gpu_seed = False usually improves accuracy, there is a decrease in throughput that makes this setting undesirable in most scenarios. Only set this hyperparameter to false if the default settings are causing significant accuracy degradation.
Composability#
As a general rule, combining several regularization methods may have diminishing returns and can even degrade accuracy. This may hold true when combining block-wise stochastic depth with other regularization methods.
Stochastic depth decreases forward and backward pass time, increasing GPU throughput. In doing so, it may cause data loading to become a bottleneck.
Code#
- class composer.algorithms.stochastic_depth.StochasticDepth(target_layer_name, stochastic_method='block', drop_rate=0.2, drop_distribution='linear', drop_warmup=0.0, use_same_gpu_seed=True)[source]
Applies Stochastic Depth (Huang et al, 2016) to the specified model.
The algorithm replaces the specified target layer with a stochastic version of the layer. The stochastic layer will randomly drop either samples or the layer itself depending on the stochastic method specified. The block-wise version follows the original paper. The sample-wise version follows the implementation used for EfficientNet in the Tensorflow/TPU repo.
Runs on
INIT, as well asBATCH_STARTifdrop_warmup > 0.Note
Stochastic Depth only works on instances of torchvision.models.resnet.ResNet for now.
- Parameters
target_layer_name (str) – Block to replace with a stochastic block equivalent. The name must be registered in
STOCHASTIC_LAYER_MAPPINGdictionary with the target layer class and the stochastic layer class. Currently, onlytorchvision.models.resnet.Bottleneckis supported.stochastic_method (str, optional) – The version of stochastic depth to use.
"block"randomly drops blocks during training."sample"randomly drops samples within a block during training. Default:"block".drop_rate (float, optional) – The base probability of dropping a layer or sample. Must be between 0.0 and 1.0. Default:
0.2.drop_distribution (str, optional) – How
drop_rateis distributed across layers. Value must be one of"uniform"or"linear"."uniform"assigns the samedrop_rateacross all layers."linear"linearly increases the drop rate across layer depth starting with 0 drop rate and ending withdrop_rate. Default:"linear".drop_warmup (str | Time | float, optional) – A
Timeobject, time-string, or float on [0.0; 1.0] representing the fraction of the training duration to linearly increase the drop probability to linear_drop_rate. Default:0.0.use_same_gpu_seed (bool, optional) – Set to
Trueto have the same layers dropped across GPUs when using multi-GPU training. Set toFalseto have each GPU drop a different set of layers. Only used with"block"stochastic method. Default:True.
- apply(event, state, logger)[source]
Applies StochasticDepth modification to the state’s model.
- match(event, state)[source]
Run on
INIT, as well asBATCH_STARTifdrop_warmup > 0.- Args:
event (Event): The current event. state (State): The current state.
- Returns:
bool: True if this algorithm should run now.
- composer.algorithms.stochastic_depth.apply_stochastic_depth(model, target_layer_name, stochastic_method='block', drop_rate=0.2, drop_distribution='linear', use_same_gpu_seed=True, optimizers=None)[source]
Applies Stochastic Depth (Huang et al, 2016) to the specified model.
The algorithm replaces the specified target layer with a stochastic version of the layer. The stochastic layer will randomly drop either samples or the layer itself depending on the stochastic method specified. The block-wise version follows the original paper. The sample-wise version follows the implementation used for EfficientNet in the Tensorflow/TPU repo.
Note
Stochastic Depth only works on instances of torchvision.models.resnet.ResNet for now.
- Parameters
model (Module) – model containing modules to be replaced with stochastic versions
target_layer_name (str) – Block to replace with a stochastic block equivalent. The name must be registered in
STOCHASTIC_LAYER_MAPPINGdictionary with the target layer class and the stochastic layer class. Currently, onlytorchvision.models.resnet.Bottleneckis supported.stochastic_method (str, optional) – The version of stochastic depth to use.
"block"randomly drops blocks during training."sample"randomly drops samples within a block during training. Default:"block".drop_rate (float, optional) – The base probability of dropping a layer or sample. Must be between 0.0 and 1.0. Default: 0.2`.
drop_distribution (str, optional) – How
drop_rateis distributed across layers. Value must be one of"uniform"or"linear"."uniform"assigns the samedrop_rateacross all layers."linear"linearly increases the drop rate across layer depth starting with 0 drop rate and ending withdrop_rate. Default:"linear".use_same_gpu_seed (bool, optional) – Set to
Trueto have the same layers dropped across GPUs when using multi-GPU training. Set toFalseto have each GPU drop a different set of layers. Only used with"block"stochastic method. Default:True.optimizers (Optimizer | Sequence[Optimizer], optional) –
Existing optimizers bound to
model.parameters(). All optimizers that have already been constructed withmodel.parameters()must be specified here so they will optimize the correct parameters.If the optimizer(s) are constructed after calling this function, then it is safe to omit this parameter. These optimizers will see the correct model parameters.
- Returns
The modified model
Example
import composer.functional as cf from torchvision import models model = models.resnet50() cf.apply_stochastic_depth(model, target_layer_name='ResNetBottleneck')